
In today’s collaborative biopharma landscape, external partners are integral to R&D and manufacturing. These include contract research organizations (CROs), contract development and manufacturing organizations (CDMOs), and contract manufacturing organizations (CMOs). But when it comes to data, these partnerships often introduce more complexity than clarity. From spreadsheets in email attachments to handwritten notes in scanned PDFs, the formats are as varied as the workflows—and just as fragmented.
For scientific, IT, and data leaders, integrating this torrent of external data into internal systems for analysis, quality review, or regulatory filing is a persistent challenge. But it’s also a solvable one.
The External Data Problem Isn’t Just External
Managing data from CRO/CDMO/CMOs mirrors many of the same challenges biopharmas face internally:
- Heterogeneous data types from a multitude of instruments and assays
- Lack of standardized formats across partners
- Missing context and poor traceability
- Manual, error-prone transfers via email, SharePoint, or File Transfer Protocol (FTP)
The result? Data that’s hard to search, validate, or use—and certainly not ready for analytics or AI.
As the volume and importance of outsourced work grows, so does the urgency of solving this integration bottleneck. And the answer lies in moving beyond basic file handling toward intelligent, automated data engineering.
Best Practices for External Data Management
Solving the external data challenge starts with adopting a new mindset—one that treats data not as a deliverable, but as an engineered asset. The most effective biopharma organizations are embracing a set of best practices that prioritize automation, context, traceability, and usability. Here’s how TetraScience helps bring these principles to life:
1. Automate Ingestion from External Systems
Manual file transfers via email or FTP are a recipe for delays, errors, and lost context. TetraScience eliminates these brittle handoffs by providing automated connectors, like the SharePoint Connector, that continuously monitor uploads and transfer raw files directly into the Tetra Scientific Data and AI Cloud. No manual intervention is required.
2. Harmonize Data with Vendor-Agnostic Formats
Once ingested, raw data is processed through pipelines that convert it into an open, vendor-agnostic JSON file, structured using an Intermediate Data Schema (IDS). This harmonization step ensures consistency across data types, experiments, and partner sources. It also enables enterprise-wide searchability, reuse, and analytics readiness.
3. Preserve Scientific Context and Lineage
Understanding how data was generated is as important as the data itself. That’s why every dataset in the Tetra Scientific Data and AI Cloud retains metadata labels, provenance, and data lineage—whether it originated from a CRO spreadsheet or a scanned PDF from a CMO. Stakeholders can see exactly where the data came from and how it was processed.
4. Build In Human Oversight Where It Matters
Automation doesn't mean eliminating scientists from the process; it means freeing them to focus on quality and insight. TetraScience enables human-in-the-loop workflows with review and validation steps that allow users to approve or reject incoming data before it’s sent to downstream systems, such as ELNs or analytics platforms.
5. Enable Downstream Consumption at Scale
Once the data has been engineered and approved, it can be automatically sent to platforms like Benchling, Snowflake, or visualization apps within the Tetra Data and AI Workspace. This ensures that scientists, analysts, and decision-makers can work with clean, structured data exactly where they need it—without delays or manual rework.
Putting Best Practices into Action
The following examples show how biopharma organizations can apply the best practices outlined above using TetraScience solutions, turning fragmented partner data into reliable, analytics-ready assets.
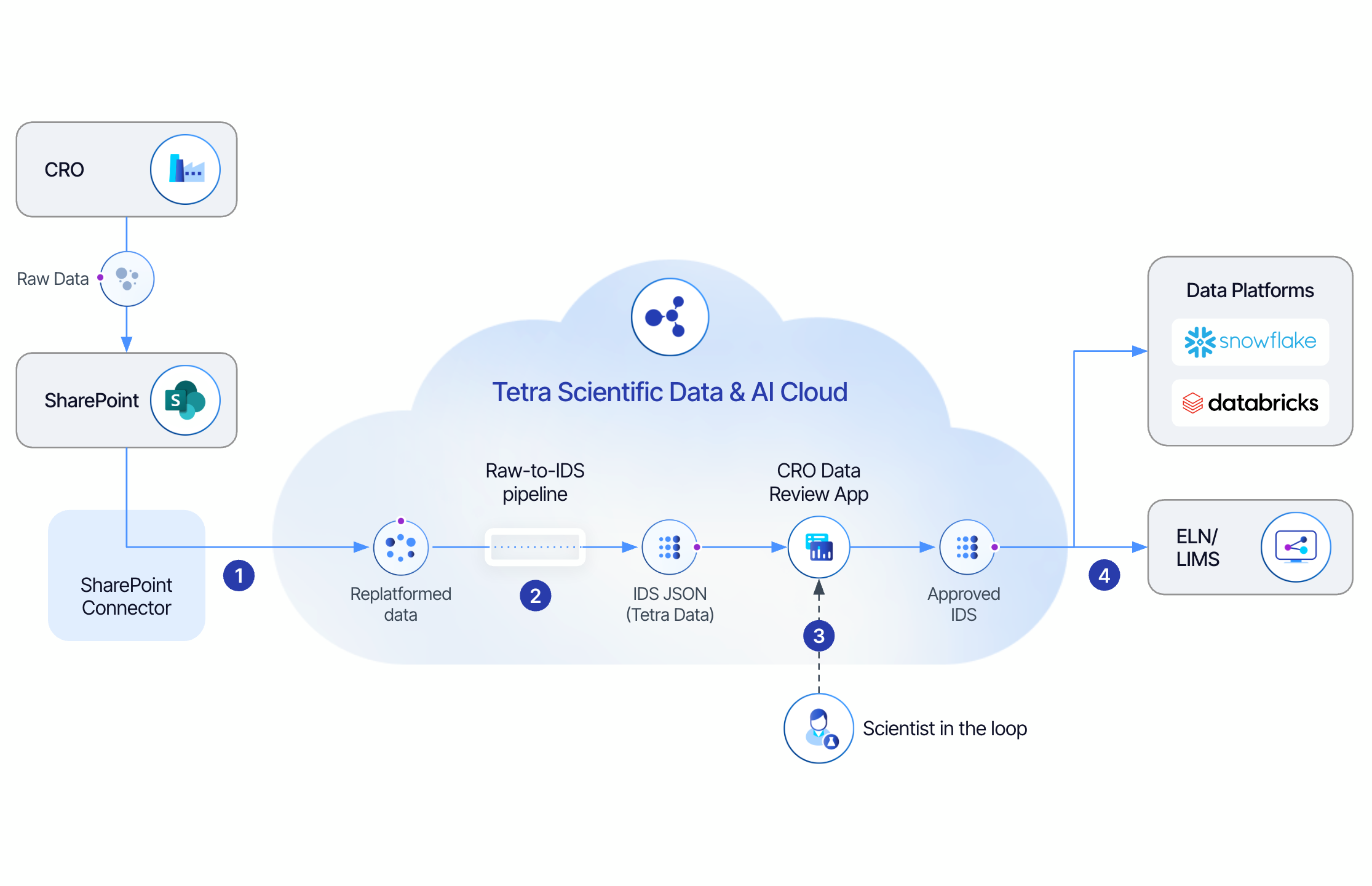
Automating and Reviewing CRO Data
- Replatforming: CRO uploads experimental data to SharePoint, and the Tetra SharePoint Connector automatically uploads it to the cloud.
- Engineering: Data is transformed into an open, vendor-agnostic JSON format using an IDS. This Tetra Data is optimized for downstream analysis, including advanced analytics and AI.
- Review: Scientists use a review app to assess and approve or reject datasets.
- Consumption: Approved data is automatically sent to ELNs, LIMS, or data platforms such as Snowflake or Databricks.
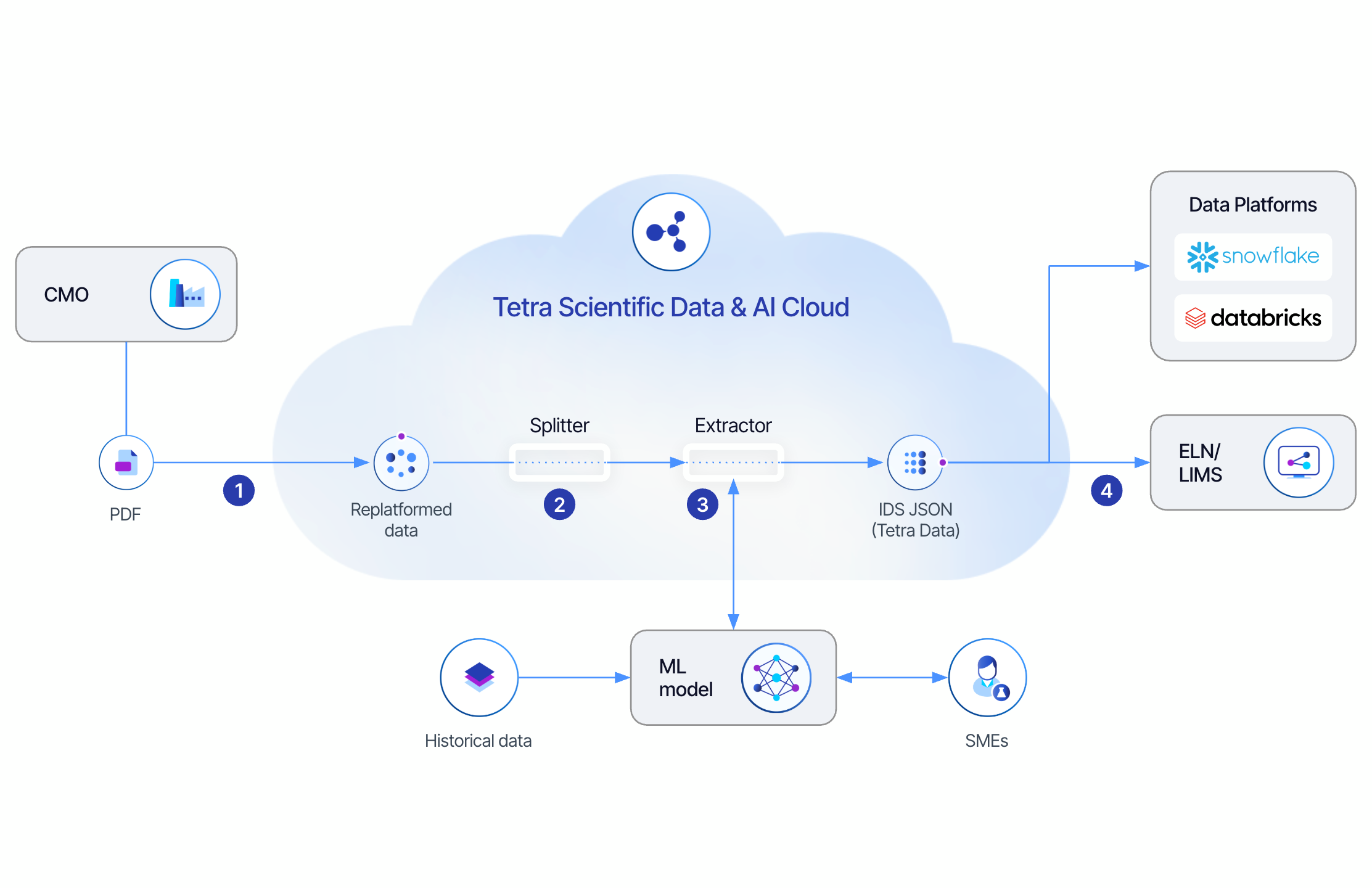
Extracting and Harmonizing CMO PDF Data
- Replatforming: PDF files from the CMO are ingested into the Tetra Scientific Data and AI Cloud.
- Splitting: A Splitter pipeline identifies and separates relevant sections of the PDF, extracting only the pages with data of interest.
- Extraction: The Extractor pipeline uses an ML model trained on historical datasets and guided by subject matter experts (SMEs) to pull out key-value pairs (from both printed and handwritten fields), enrich the data with metadata labels, and engineer it into Tetra Data.
- Consumption: The engineered data is now searchable, traceable, and available for downstream applications.
Why This Matters
Disjointed, low-context partner data slows everything: scientific analysis, QC decisions, regulatory filings, and even batch release. Worse, it creates compliance risks and delays in uncovering anomalies or trends.
By automating ingestion, harmonization, and contextualization, while preserving scientist oversight where it matters most, biopharmas can:
- Accelerate decision-making
- Ensure data integrity
- Enable analytics and AI at scale
- Reduce manual effort and compliance risk
Don’t Just Manage External Data. Engineer It.
TetraScience applies its enterprise-scale scientific data expertise to transform external partner data from a liability into a strategic asset. Whether it’s harmonizing CRO spreadsheets or parsing CMO PDFs, the goal is the same: unlock clean, contextual, analytics-ready data—without compromise.