The crisis isn't biological or financial. It's architectural—and the people who understand this best are the ones living with the consequences.
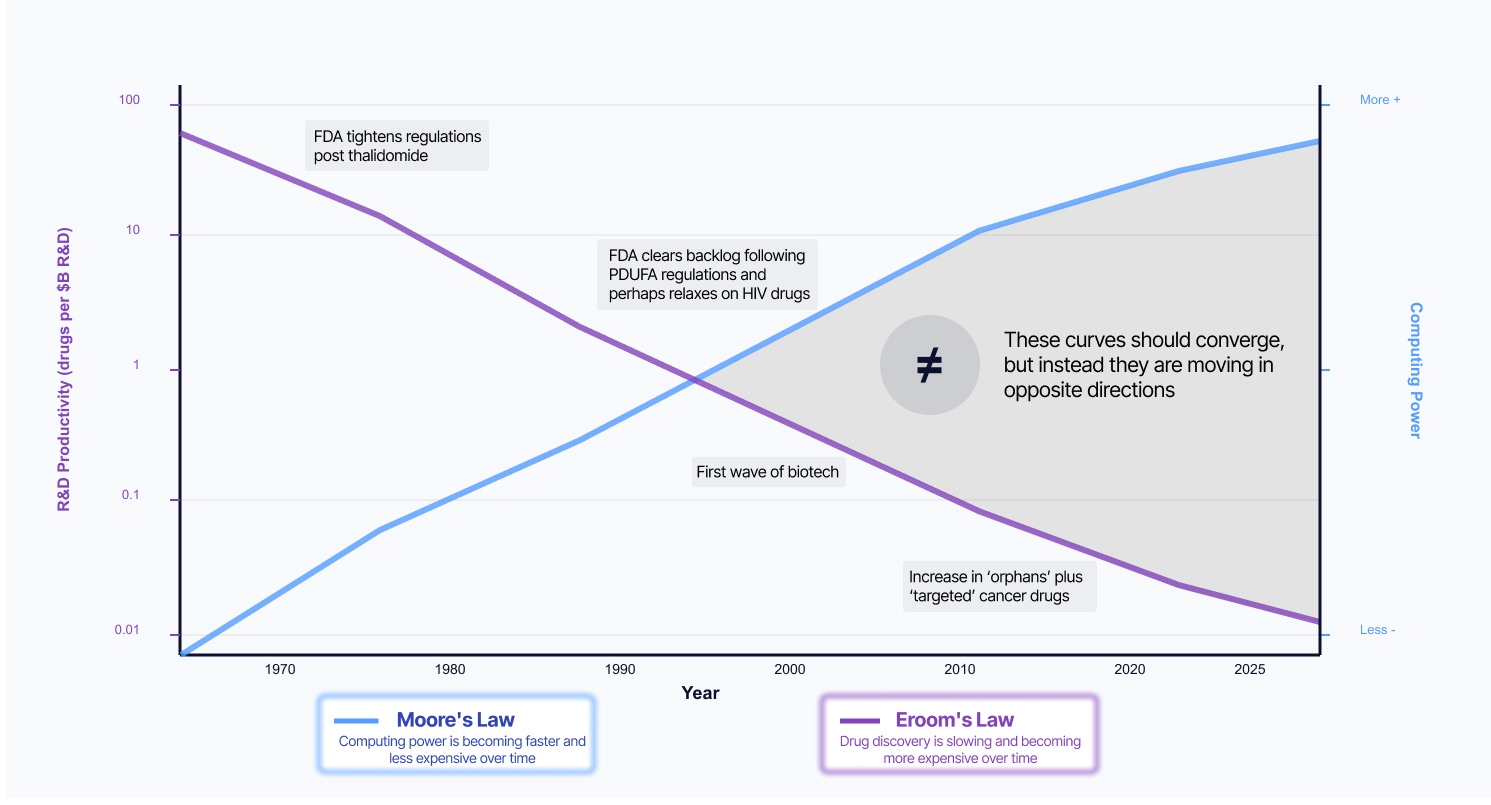
You've probably intuited this: the industry wastes billions solving the same problems because the economic incentives push everyone toward proprietary solutions for commodity infrastructure. What if 90% of the R&D stack was treated as shared infrastructure instead of competitive moats?
The answer isn't better software. It's a different architecture: standardized, AI-native infrastructure that lets organizations compound on shared innovation instead of duplicating the same integrations and analyses.
This is about liberating expertise, not replacing it, and giving scientists back the time currently consumed by digital janitorial work so they can focus on what you went into this field to do: discover.

.jpg)