
The challenges
The boom in AI technologies is shaping the way we think, work, and solve problems. Even little things in life, like how to tend to a cut on the finger, can be consulted with an AI chatbot. We use AI without thinking too much about how the data is crawled, sanitized, tokenized, learned, analyzed, and finally, represented to us. But not all data is AI-ready out of the box. We still live with heterogeneous, incompatible data formats, structured or unstructured, proprietary, and vendor-locked. Without acquiring, parsing, and harmonizing, the data does not comply with the FAIR principles (findability, accessibility, interoperability, reusability) and is unfit for AI.

Proprietary or vendor-locked file formats often require specific vendor software to access the data. We've heard countless stories of researchers needing to physically go into the lab, even during peak COVID restrictions, simply because the necessary software was only installed on lab computers. But even when file formats aren’t proprietary, they can still present significant challenges.
Take a familiar example: the TXT file. While it's intuitive and easy for humans to read and edit, it's far less friendly to machines. TXT files lack a defined structure or schema, forcing parsers to make assumptions about where the headers are, what the delimiters might be, how to interpret empty lines, and so on. Anyone can open and modify a TXT file with complete freedom, which makes it incredibly flexible, but also fragile. A single unexpected line can break the entire parsing logic. When it comes to data structure, freedom and rigor often sit at opposite ends of the spectrum.
The vendor-agnostic Intermediate Data Schema
With over a decade in the industry, TetraScience has encountered hundreds of instruments and data formats. We realized that, to unlock the power of Machine Learning and AI, providing machine-readable and vendor-agnostic data is key. Therefore, we introduced the concept “Intermediate Data Schema” or IDS in the very beginning (we have a blog post explaining the IDS concept in detail). The IDS designed by TetraScience in collaboration with instrument manufacturers, scientists, and customers is an open, vendor-agnostic JSON schema that is applied to raw instrument data or report files. This schema is used to map vendor-specific information (such as the name of a field) to vendor-agnostic information. The IDS standardizes naming, data type (whether the field is a string, an integer, or a date), data range (e.g., a number must be positive), and data hierarchy. IDS fields can also be linked to external ontologies to enable semantic interoperability. To ensure IDS consistency, TetraScience has been creating IDS component libraries, some of which are general to all instruments, and others are specific to a particular instrument technique or category. Therefore, creating a new IDS is like playing LEGO®; you pick the pieces from the existing building blocks and assemble them.
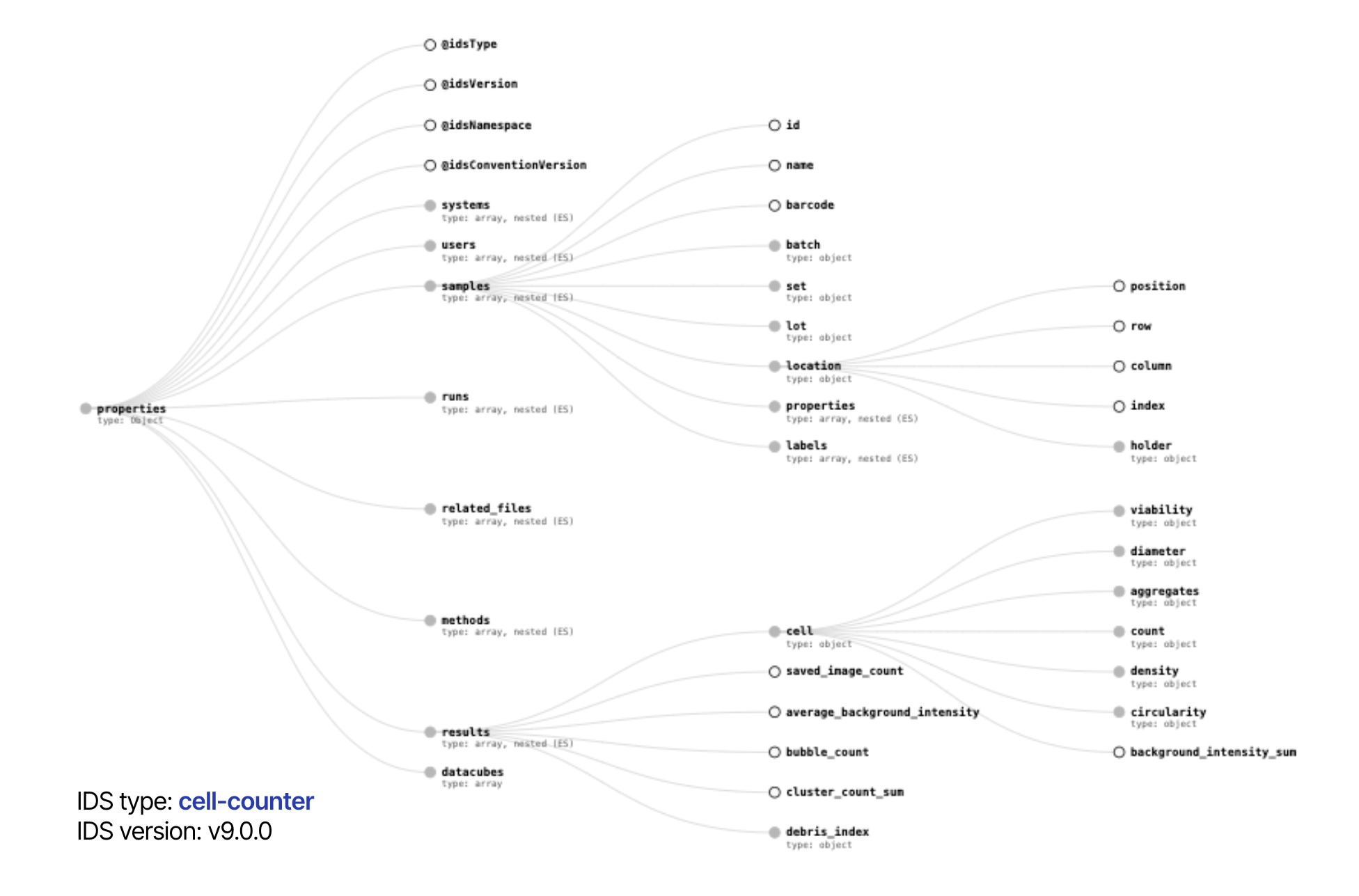
How is IDS used?
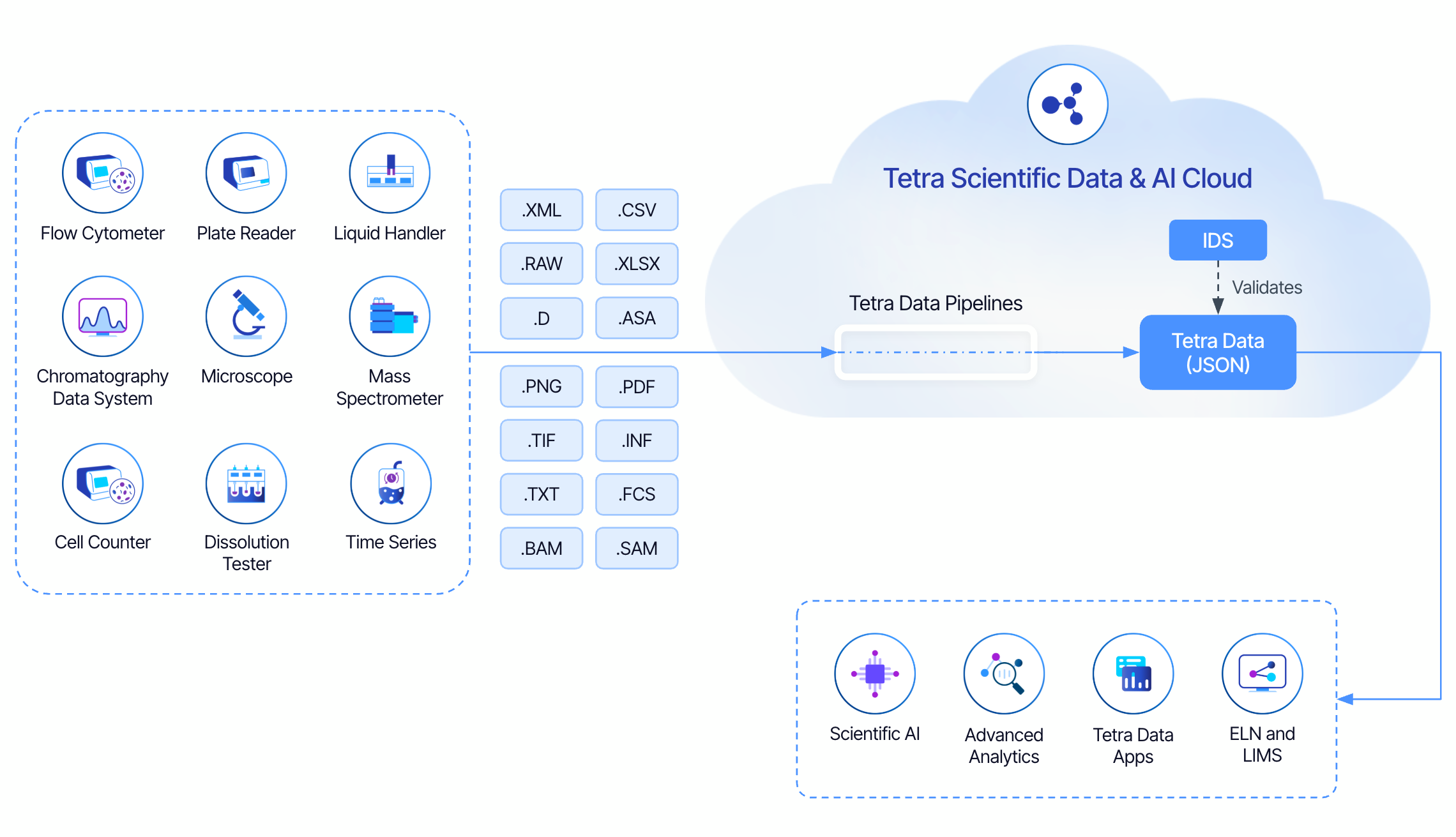
First, raw data files are uploaded to the data lake of the Tetra Data Platform (TDP), which is the core of the Tetra Scientific Data and AI Cloud. Files are then parsed by a specific data pipeline, which generates a JSON file using the IDS designed for that specific instrument or instrument category as a guide. During processing, the data is validated, and search indexes are generated. The newly generated JSON file is thus an IDS JSON.
Furthermore, the data is now fluid—it’s indexed into the Tetra Data Lake. It’s Tetra Data now. You can query the data in TDP using Elasticsearch, SQL, API calls, or port the data into any tool of your choice.
Use case ontology: why simple data parsing is not enough
While data challenges rarely exist at the level of a single instrument, scientific research projects typically require data from multiple instruments and involve collaboration across different laboratories. For retrieval, meaningful reuse, and analysis, data needs to be augmented with contextual information—such as materials-related metadata from lab inventory management systems, entry identifiers from electronic lab notebooks (ELNs), and more.
To address this critical requirement of scientists, TetraScience is solving data problems not only at the instrument level but, more importantly, at the scientific use case level. Over half of our team brings hands-on experience from the life sciences industry, enabling us to design use case–specific data models with metadata that is essential for scientific experiments and workflows. The illustration below demonstrates how individual instrument schemas are structured to support specific scientific use cases.
In the figure below, we highlight cell line development (CLD) as an example use case—a key phase in the upstream bioprocessing workflow. Within CLD, transfection studies are a critical component. Conducting a transfection study requires diverse sets of information, including cell clone attributes, transfection metrics, experimental context, material and container data, and methodological details. Some of this data originates from instrument-generated IDS files, while other elements are sourced from external systems. We have developed comprehensive data models and IDS for each of these data blocks and interconnected them through defined relationships—a framework we refer to as the TetraScience Use Case Ontology. This ontology enables the execution of transfection studies and is extensible and reusable across a wide range of scientific use cases.

The compelling advantage
The IDS harmonizes diverse scientific datasets in biopharma, including data from instruments, experimental context, and informatics systems. Because the IDS JSON files are consistent, self-describing, ontology-enabled, and vendor-agnostic, they allow companies to consume the data in their preferred applications and build searches and aggregations. Furthermore, Tetra ontologies augment data for scientific use cases beyond instrument-generated data. They seamlessly integrate the data into visualization and analysis software, as well as ML/AI applications. The flywheel is turning and momentum is building because AI compels customers to recognize and demand what should have always been available: liberated, vendor-agnostic data, free from silos. Leveraging the Tetra Scientific Data and AI Cloud, you can unlock the insights from your data and uncover new possibilities.